FastApi框架
一个用于构建 API 的现代、快速(高性能)的web框架
核心组件
Starlette 一种轻量级的ASGI框架/工具包
Pydantic 基于Python类型提示来定义数据验证、序列化和文档的库
HTTP协议
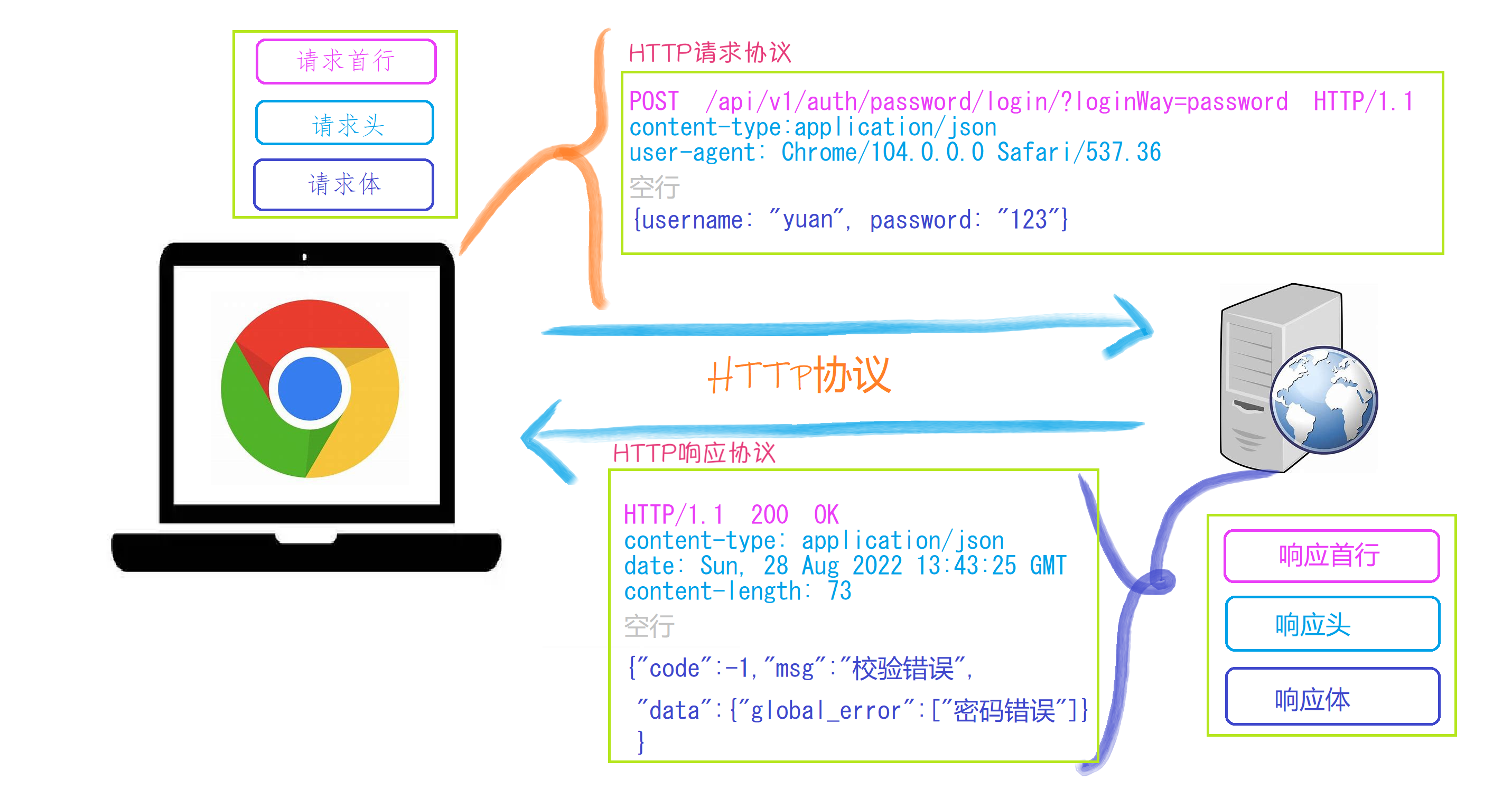
快速构建
关键词
虚拟环境创建,项目文件结构,路由分发,路径参数
(一)虚拟环境
text
workon 查看当前有哪些虚拟环境
查看python解释器位置
windows系统:
where python
苹果系统:
which python相关命令
text
创建虚拟环境: mkvirtualenv 虚拟环境名称
创建虚拟环境(指定python版本): mkvirtualenv -p python3 虚拟环境名称
查看所有虚拟环境: workon+2次tab键
使用虚拟环境: workon 虚拟环境名称
退出虚拟环境: deactivate
删除虚拟环境(必须先退出虚拟环境内部才能删除当前虚拟环境):
rmvirtualenv 虚拟环境名称
其他相关命令:
查看虚拟环境中安装的包: pip freeze 或者 pip list
收集当前环境中安装的包及其版本: pip freeze > requirements.txt
在部署项目的服务器中安装项目使用的模块: pip install -r requirements.txt(重要文件)
``
提示:
- 虚拟环境只会管理环境内部的python模块和python解析器,对于源代码是毫无关系
- 创建虚拟环境需要联网
- 创建成功后, 会自动工作在这个虚拟环境上
- 工作在虚拟环境上, 提示符最前面会出现 “(虚拟环境名称)”(二)项目文件结构
方案1 功能划分
text
my_project/
├── app/
│ ├── users/ # 用户模块
│ │ ├── __init__.py
│ │ ├── models.py # 用户模型
│ │ ├── schemas.py # 用户的Pydantic模式
│ │ ├── crud.py # 用户数据库操作
│ │ ├── endpoints.py # 用户API路由
│ │ └── services.py # 用户相关的业务逻辑
│ ├── products/ # 产品模块
│ │ ├── __init__.py
│ │ ├── models.py # 产品模型
│ │ ├── schemas.py # 产品的Pydantic模式
│ │ ├── crud.py # 产品数据库操作
│ │ ├── endpoints.py # 产品API路由
│ │ └── services.py # 产品相关的业务逻辑
│ ├── orders/ # 订单模块
│ │ ├── __init__.py
│ │ ├── models.py # 订单模型
│ │ ├── schemas.py # 订单的Pydantic模式
│ │ ├── crud.py # 订单数据库操作
│ │ ├── endpoints.py # 订单API路由
│ │ └── services.py # 订单相关的业务逻辑
│ ├── core/ # 核心模块(配置、认证等)
│ │ ├── config.py # 配置文件
│ │ ├── security.py # 权限管理、认证相关
│ │ └── __init__.py
│ ├── db/ # 数据库相关
│ │ ├── models.py # 数据库模型
│ │ ├── session.py # 数据库会话管理
│ │ ├── migrations/ # Alembic迁移文件
│ │ └── __init__.py
│ ├── main.py # FastAPI应用实例
│ └── __init__.py
├── alembic.ini # Alembic配置文件
├── requirements.txt # 依赖文件
└── README.md # 项目文档方案2 层级划分
te
my_project/
├── app/
│ ├── controllers/ # 控制器层,处理请求和响应
│ │ ├── __init__.py
│ │ ├── users.py # 用户相关API
│ │ ├── products.py # 产品相关API
│ │ └── orders.py # 订单相关API
│ ├── services/ # 业务逻辑层
│ │ ├── __init__.py
│ │ ├── user_service.py # 用户业务逻辑
│ │ ├── product_service.py # 产品业务逻辑
│ │ └── order_service.py # 订单业务逻辑
│ ├── repositories/ # 数据访问层,CRUD操作
│ │ ├── __init__.py
│ │ ├── user_repository.py # 用户数据访问
│ │ ├── product_repository.py# 产品数据访问
│ │ └── order_repository.py # 订单数据访问
│ ├── models/ # 数据模型
│ │ ├── __init__.py
│ │ ├── user.py # 用户模型
│ │ ├── product.py # 产品模型
│ │ └── order.py # 订单模型
│ ├── schemas/ # 请求和响应模式
│ │ ├── __init__.py
│ │ ├── user_schema.py # 用户Pydantic模式
│ │ ├── product_schema.py # 产品Pydantic模式
│ │ └── order_schema.py # 订单Pydantic模式
│ ├── db/ # 数据库配置
│ │ ├── __init__.py
│ │ ├── session.py # 数据库会话管理
│ │ └── migrations/ # Alembic迁移文件
│ ├── main.py # FastAPI应用实例
│ └── __init__.py
├── alembic.ini # Alembic配置文件
├── requirements.txt # 依赖文件
└── README.md # 项目文档(三)路由分发
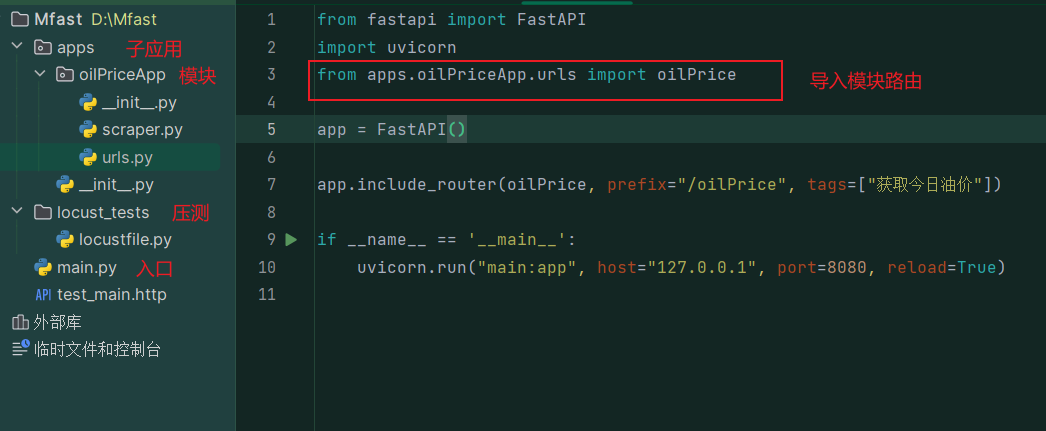
python
# main.py
# 从自应用apps文件夹下的各个模块引入路由文件,并导出
from fastapi import FastAPI
from apps.oilPriceApp.urls import oilPrice
from apps.userApp.urls import student_api
app = FastAPI()
# include_router注册
app.include_router(oilPrice, prefix="/oilPrice", tags=["功能接口"])
app.include_router(student_api, prefix="/student", tags=["学生管理"])
# 额外属性
# dependencies 用于为路由组添加公共依赖。所有通过该 router 注册的路径都会使用这些依赖项。
# responses 可以为路由组添加默认的响应模型。这对于在整个路由组中应用通用的响应格式非常有用。
# response_model 用于设置路由组的默认响应模型。当你包含一个路由时,可以指定它的返回类型。
# status_code 用于设置路由组的默认状态码。这在某些情况下有用,比如你希望整个路由组的响应都返回某个特定的 HTTP 状态码。
# default_response_class 用于设置路由组的默认响应类。FastAPI 会使用这个类来处理所有的响应(如 JSON 响应,HTML 响应等)。
# response_headers 用于设置路由组的所有响应的默认响应头。这对某些需要特定 header 的 API 非常有用。
# include_in_schema 用于决定该路由组是否应该出现在 OpenAPI 文档中。如果设为 False,该路由组将不会出现在生成的 API 文档中。
# version 用于设置路由的版本,可以在路由的路径中自动包含版本号,帮助你在多版本 API 中区分不同版本的接口。(四)参数
路径参数
路径参数是在URL的路径中指定的参数。它们通常用于标识资源,例如用户ID或产品ID
python@app.get("/items/{item_id}") async def read_item(item_id: int): ...查询参数
python# 在路径参数中没有的参数,就是查询参数 @app.get("/items/") async def read_item(skip: int = 0, limit: int = 10): ...默认参数
python@oilPrice.post("/api/test/{a}") async def test(a, b=None, c=None): # 没有默认参数即必选项 return {"a": a, "b": b, "c": c}响应参数
pythonfrom pydantic import BaseModel, EmailStr from typing import Optional, Union class UserIn(BaseModel): name: str email: EmailStr password: str full_name: Union[str, None] = None class UserOut(BaseModel): name: str email: EmailStr full_name: Union[str, None] = None # 用于指定函数的响应模型。响应模型是一个 Pydantic 模型,用于定义函数返回的数据的结构和验证 # response_model_exclude_unset 是 FastAPI 中的一个参数,用于控制是否在响应中排除未设置的属性。 @oilPrice.post("/user", summary="校验", response_model=UserOut, response_model_exclude_unset=True) async def create_user(user: UserIn): return user
(五)示例
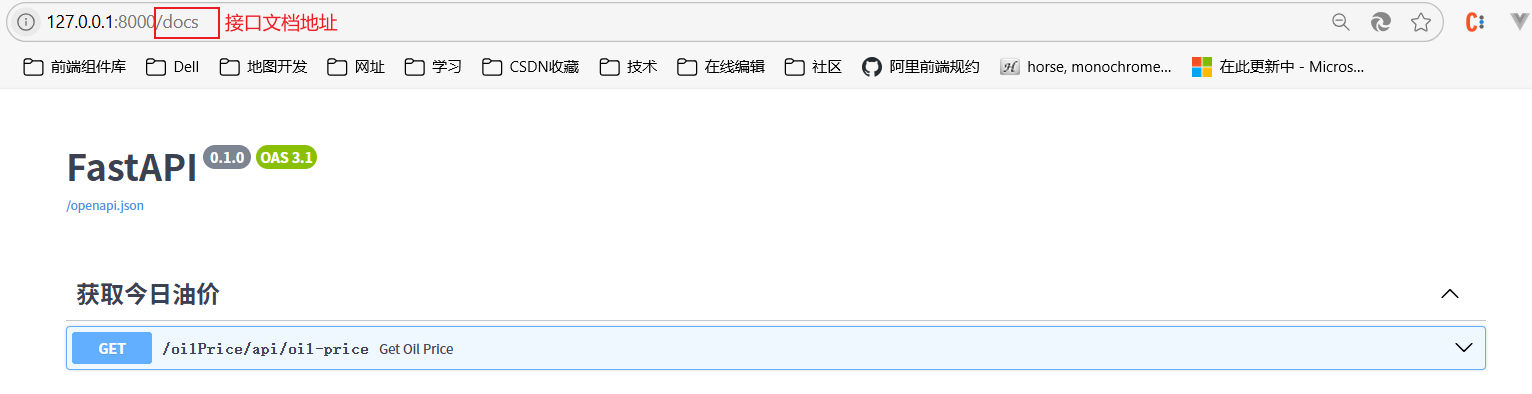
爬取目标网址,获取今日油价
获取今日油价
思路:根据爬取页面的目标地址,分析页面存储油价标签的元素标签,引入BeautifulSoup库,分析页面,抓取油价信息。
python
# scraper.py
import requests
from bs4 import BeautifulSoup
def fetch_oil_price(address):
# 动态构建URL,地址作为路径的一部分
url = f"http://xxxxx/{address}/" # 根据传入的地址动态构建 URL
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/115.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers, timeout=5)
response = requests.get(url)
# 显式设置响应内容的编码为 GBK(针对国内网站的常见编码)
response.encoding = 'gbk'
response.raise_for_status() # 检查请求是否成功
soup = BeautifulSoup(response.text, 'html.parser')
# cpbaojia标签存储油价信息
exposition = soup.find("div", class_="cpbaojia")
if not exposition:
raise ValueError("未查询到油价信息") # 未找到 class_ 为 cpbaojia 的父级元素
# 找到包含油价的表格
oil_price_table = exposition.find("table", width="98%") # 通过宽度来定位表格,您可以根据实际情况修改选择器
if not oil_price_table:
raise ValueError("未找到油价表格")
oil_prices = {}
# 遍历表格中的所有行(跳过标题行)
rows = oil_price_table.find_all("tr")[2:] # 第一行是标题,第二行是日期,所以从第三行开始处理
for row in rows:
columns = row.find_all("td")
if len(columns) >= 4: # 确保每一行有至少4列
fuel_name = columns[0].get_text(strip=True) # 油品名称(如:江苏92#汽油)
price = columns[1].get_text(strip=True) # 价格
oil_prices[fuel_name] = price
return oil_pricespython
# urls.py
from fastapi import APIRouter, HTTPException, Query
from .scraper import fetch_oil_price
from typing import Optional
from fastapi.responses import JSONResponse
oilPrice = APIRouter()
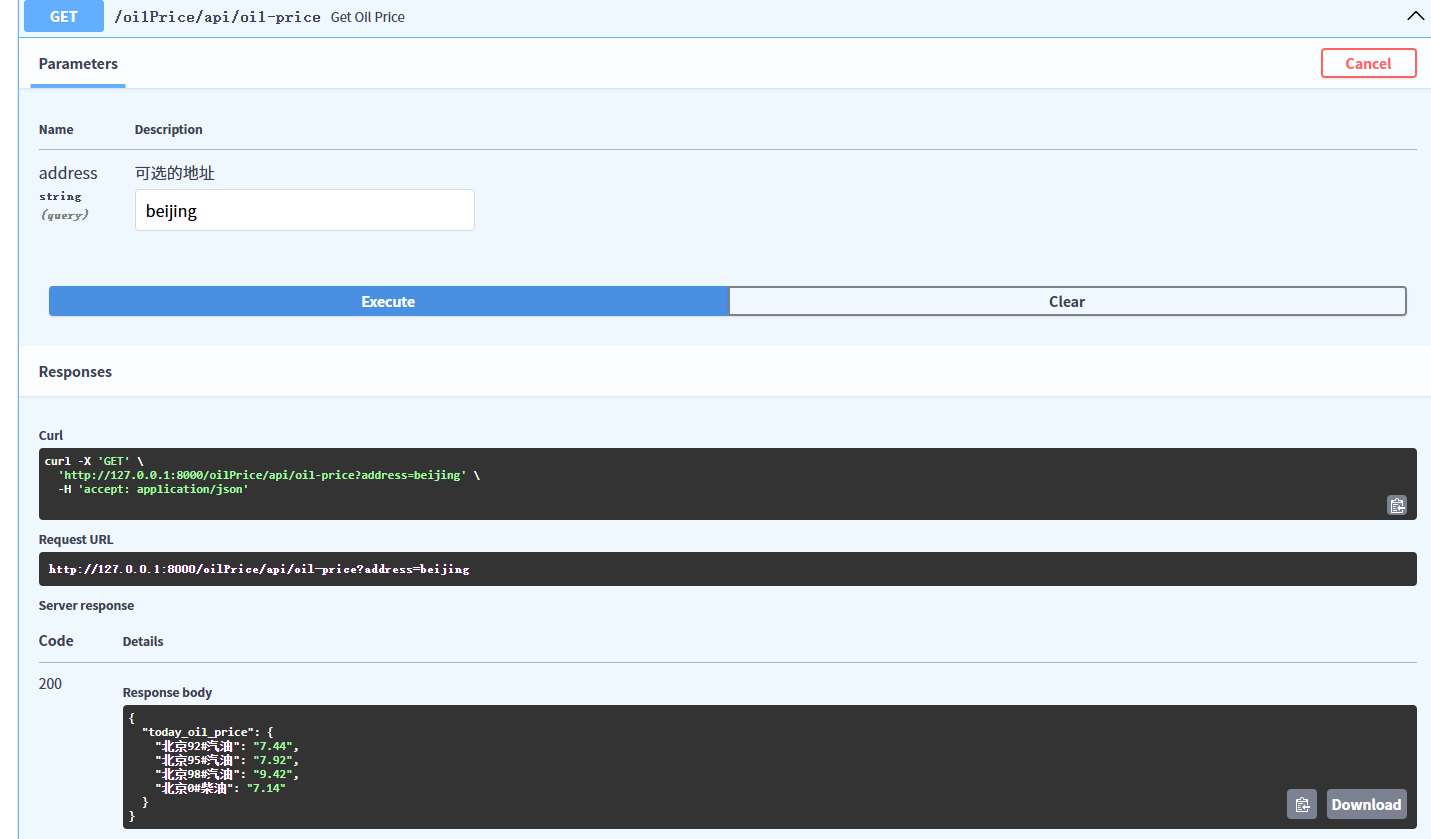
@oilPrice.get("/api/oil-price")
async def get_oil_price(address: Optional[str] = Query(None, description="可选的地址")):
if not address:
# 使用 JSONResponse 来返回自定义格式
return JSONResponse(
status_code=400,
content={"errorMsg": "请输入想要查询省份小写拼英地址"}
)
try:
# 将地址传递给爬取函数,获取对应的油价数据
price = fetch_oil_price(address)
return {"today_oil_price": price}
except Exception as e:
# 异常情况的自定义错误信息
return JSONResponse(
status_code=500,
content={"errorMsg": f"获取油价失败: {str(e)}"}
)
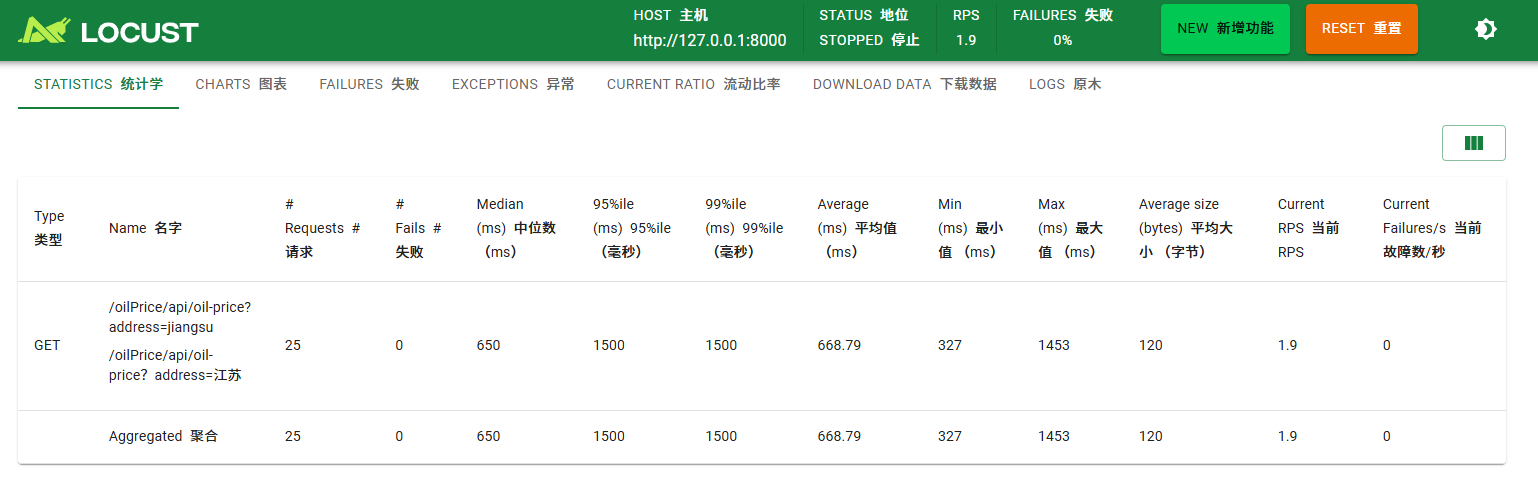
 压测
压测
python
# locust_tests/locustfile.py
# 压测
from locust import HttpUser, task, between
class OilPriceUser(HttpUser):
# 设置用户之间的等待时间,模拟间隔请求
wait_time = between(1, 5) # 等待 1-5 秒
@task
def get_oil_price(self):
# 向你的 FastAPI 接口发送 GET 请求
response = self.client.get("/oilPrice/api/oil-price?address=jiangsu")
# 检查响应状态码是否为 200
if response.status_code == 200:
print("成功获取油价数据")
else:
print(f"请求失败: {response.status_code}")
查询
代码片段
python
# models.py
class Student(Model):
id = fields.IntField(pk=True)
sno = fields.IntField(description='学号')
pwd = fields.CharField(max_length=255, description='密码')
name = fields.CharField(max_length=255, description='姓名')
# 一对多
clas = fields.ForeignKeyField('models.Clas', related_name='students')
# 多对多
courses = fields.ManyToManyField('models.Course', related_name='students', description='学生选课表')
# urls.py
from apps.userApp.models import Student
# 查询
@student_api.get("/")
async def getAllStudents():
students = await Student.all()
return {
"data": students
}基础语法:
python
# 获取模型表中的所有记录。
students = await Student.all()
# 查找所有名字包含 '李' 的学生
students = await Student.filter(name__icontains="李")
# 查找学号大于 100 的学生
students = await Student.filter(sno__gt=100)
# 查找所有学号不大于 100 的学生
students = await Student.exclude(sno__lte=100)
# 查找一个学号为 100 的学生
# get 用于查找符合条件的唯一一条记录。如果查询到多条记录或没有记录,会抛出 DoesNotExist 或 MultipleObjectsReturned 错误。
student = await Student.get(sno=100)
# 只返回学生的姓名和学号
# .values() 方法用于选择查询的字段,并返回字典形式的结果。
students = await Student.all().values("name", "sno")
# .order_by() 用于对查询结果进行排序。
# 可以传入字段名称,默认为升序,前面加 - 表示降序。
# 按照学号升序排列
students = await Student.all().order_by("sno")
# 按照学号降序排列
students = await Student.all().order_by("-sno")
# .limit() 用于限制查询结果的数量 .offset() 用于跳过一定数量的结果。
# 查询前 10 个学生
students = await Student.all().limit(10)
# 查询第 11 到第 20 个学生
students = await Student.all().offset(10).limit(10)查询操作符
| 操作符 | 说明 | 示例 |
|---|---|---|
__gt | 大于 (greater than) | Student.filter(age__gt=18) |
__gte | 大于等于 (greater than or equal to) | Student.filter(age__gte=18) |
__lt | 小于 (less than) | Student.filter(age__lt=18) |
__lte | 小于等于 (less than or equal to) | Student.filter(age__lte=18) |
__eq | 等于 (equal to) | Student.filter(name__eq='张三') |
__ne | 不等于 (not equal to) | Student.filter(name__ne='张三') |
__contains | 包含 (用于字符串,查找包含某个子字符串) | Student.filter(name__contains='李') |
__icontains | 不区分大小写的包含 (用于字符串) | Student.filter(name__icontains='李') |
__startswith | 以某个字符串开头 | Student.filter(name__startswith='张') |
__istartswith | 不区分大小写的开头匹配 | Student.filter(name__istartswith='张') |
__endswith | 以某个字符串结尾 | Student.filter(name__endswith='丽') |
__iendswith | 不区分大小写的结尾匹配 | Student.filter(name__iendswith='丽') |
__regex | 使用正则表达式进行匹配 | Student.filter(name__regex=r"^张\d+") |
__iregex | 不区分大小写的正则表达式匹配 | Student.filter(name__iregex=r"^张\d+") |
__in | 在指定的列表或集合中 | Student.filter(sno__in=[100, 200, 300]) |
__range | 在指定的范围内 | Student.filter(sno__range=(100, 200)) |
__isnull | 字段是否为 NULL | Student.filter(email__isnull=True) |
__isnotnull | 字段是否不为 NULL | Student.filter(email__isnotnull=True) |
& | 逻辑与 (AND) | Student.filter(age__gt=18) & Student.filter(name__icontains='李') |
| ` | ` | 逻辑或 (OR) |
__year | 针对日期的年份 | Student.filter(birthdate__year=2000) |
__month | 针对日期的月份 | Student.filter(birthdate__month=5) |
__day | 针对日期的天数 | Student.filter(birthdate__day=15) |
__hour | 针对时间的小时 | Student.filter(appointment__hour=10) |
__minute | 针对时间的分钟 | Student.filter(appointment__minute=30) |
__second | 针对时间的秒数 | Student.filter(appointment__second=0) |
__count | 统计符合条件的记录数 | await Student.all().count() |
__min | 获取符合条件的最小值 | await Student.all().min("sno") |
__max | 获取符合条件的最大值 | await Student.all().max("sno") |
进阶查询